AI 面试评分模型设计:从主观判断到量化评估的工程化方案
2026/6/15 14:47:14
采集完数据就万事大吉了吗?不是的。从网页抓下来的数据通常是"脏的"——影刀RPA采集到的价格可能带个"¥"符号,销量可能写的是"1.2万+",商品标题里可能夹了一堆空格和特殊符号。
直接写进Excel没法用。数据清洗是采集流程的必修课。
| 原始数据样本 | 问题 |
|---|---|
¥ 299.00 | 价格带货币符号,无法做数学运算 |
1.2万+ | 销量用中文缩写,不是标准数字 |
超低价 | HTML实体字符没有解码 |
冬季保暖羽绒服 | 前后有空格,影响去重和匹配 |
19901-01-01 | 日期格式错误 |
-- | 缺失值用符号填充而非空 |
¥19.9~29.9 | 价格是区间,需要取最低或最高 |
拼多多店群自动化上架方案
importredefclean_price(raw_price):"""清洗价格字段"""ifnotraw_price:returnNone# 去掉货币符号、空格cleaned=re.sub(r'[¥¥$\s,,]','',str(raw_price))# 处理价格区间,取最低价if'~'incleanedor'-'incleaned:parts=re.split(r'[~\-~]',cleaned)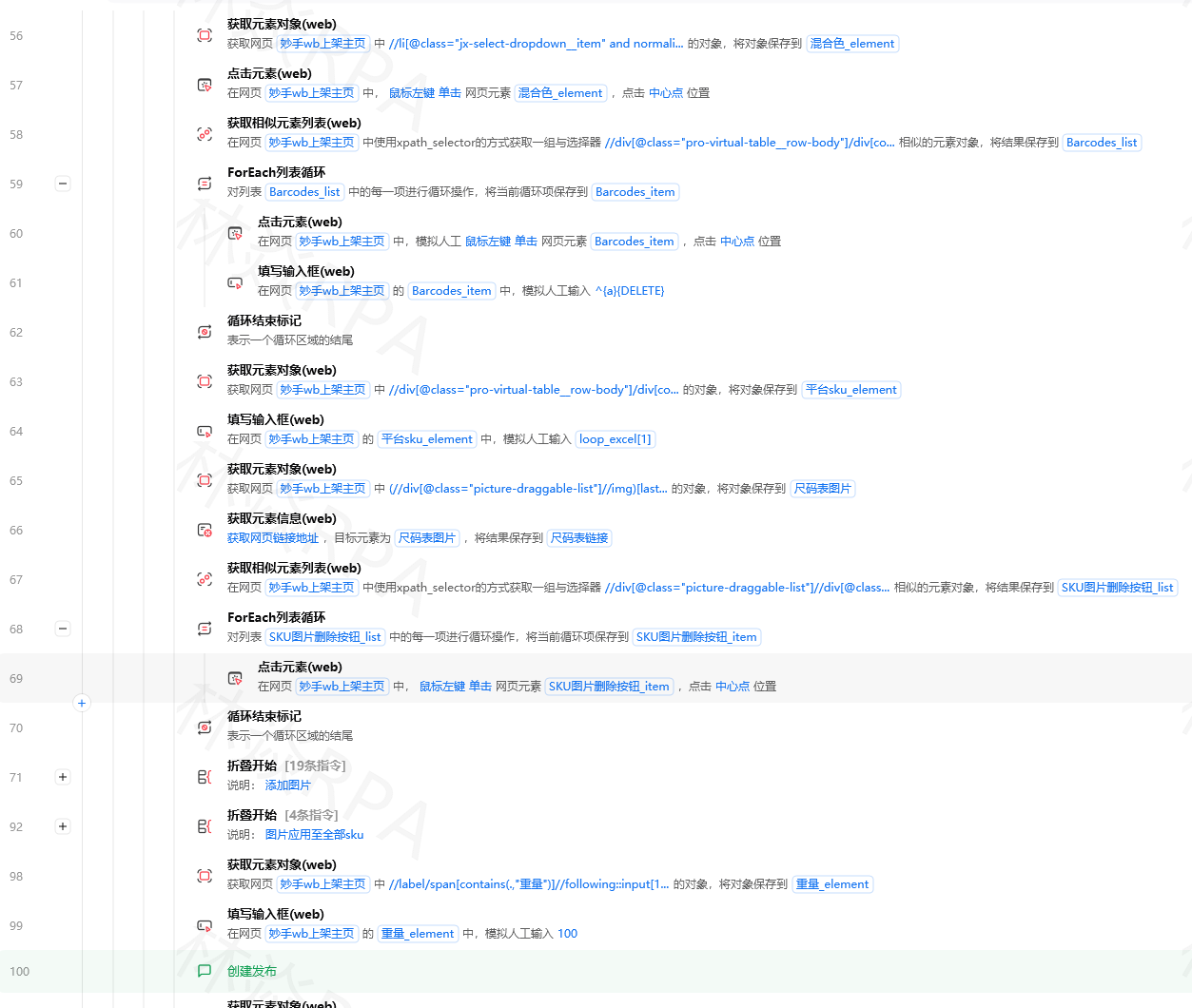cleaned=min(parts,key=lambdax:float(x)ifxelse999999)# 提取数字match=re.search(r'(\d+\.?\d*)',cleaned)returnfloat(match.group(1))ifmatchelseNone# 测试print(clean_price('¥ 299.00'))# 299.0print(clean_price('¥19.9~29.9'))# 19.9print(clean_price('--'))# Nonedefcn_number_to_int(text):"""把"1.2万+"转成12000"""ifnottext:return0text=str(text).strip().replace('+','').replace(',','')if'万'intext:num=float(text.replace('万',''))returnint(num*10000)elif'千'intext:num=float(text.replace('千',''))returnint(num*1000)elif'亿'intext:num=float(text.replace('亿',''))returnint(num*100000000)try:returnint(float(text))exceptValueError:return0# 测试print(cn_number_to_int('1.2万+'))# 12000print(cn_number_to_int('3500'))# 3500print(cn_number_to_int('2.1亿'))# 210000000importhtmldefclean_title(raw_title):"""清洗商品标题"""ifnotraw_title:return''# HTML实体字符解码title=html.unescape(raw_title)# 去掉控制字符title=re.sub(r'[\x00-\x08\x0b\x0c\x0e-\x1f\x7f]','',title)# 去掉多余空格(包括全角空格)title=re.sub(r'[\u3000\s]+',' ',title).strip()# 去掉促销词(可按需扩展)promo_words=['【限时特价】','⚡','🔥','💥','[爆款]','(推荐)']forwordinpromo_words:title=title.replace(word,'')returntitle.strip()fromdatetimeimportdatetimedefnormalize_date(raw_date):"""把各种日期格式统一成YYYY-MM-DD"""ifnotraw_date:returnNone# 尝试各种常见格式formats=['%Y-%m-%d','%Y/%m/%d','%Y.%m.%d','%m/%d/%Y','%d/%m/%Y','%Y年%m月%d日','%Y%m%d']forfmtinformats:try:returndatetime.strptime(str(raw_date).strip(),fmt).strftime('%Y-%m-%d')exceptValueError:continue# 如果都不匹配,用正则提取match=re.search(r'(\d{4})[^\d]?(\d{1,2})[^\d]?(\d{1,2})',str(raw_date))ifmatch:y,m,d=match.groups()returnf'{y}-{m.zfill(2)}-{d.zfill(2)}'returnNonedefremove_duplicates(df):"""数据去重"""# 精确去重(按标题+店铺名)df=df.drop_duplicates(subset=['标题','店铺名'],keep='first')# 去掉标题相似度极高的(简单编辑距离)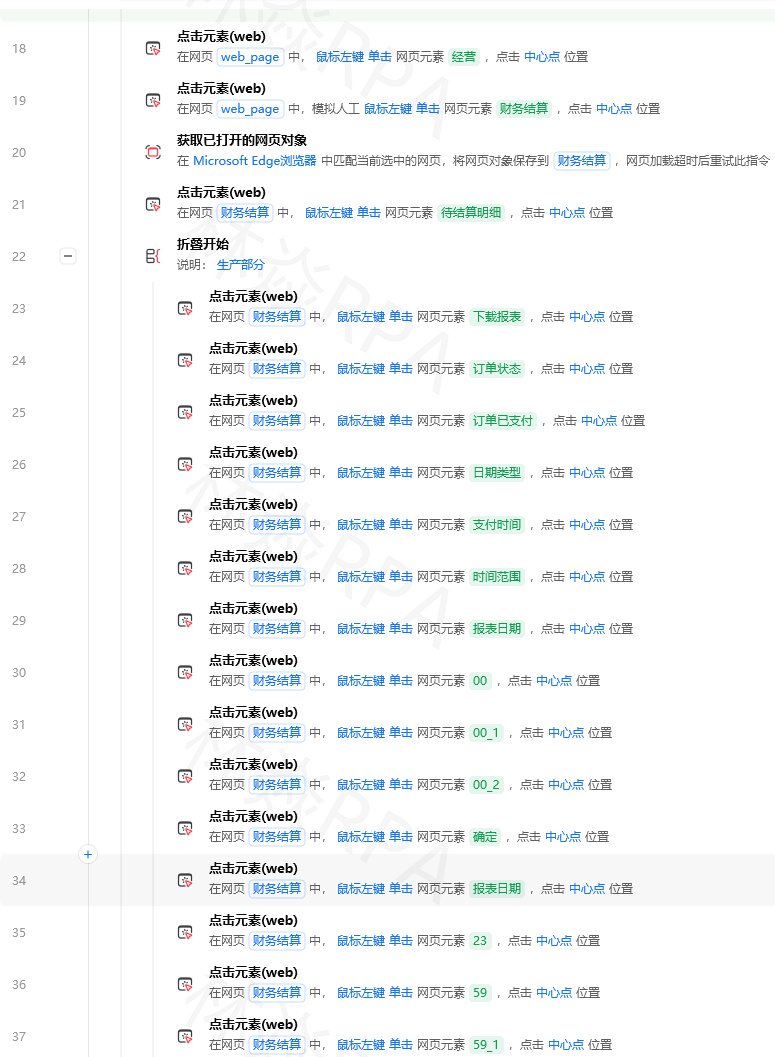# 如果不需要模糊去重,跳过这段returndf.reset_index(drop=True)defenforce_types(df):"""强制转换数据类型"""# 价格列:强制转float,失败的设为NaNdf['价格']=pd.to_numeric(df['价格'],errors='coerce')# 销量列:清洗后转intdf['销量']=df['销量'].apply(cn_number_to_int)# 日期列:统一格式df['采集时间']=pd.to_datetime(df['采集时间'],errors='coerce')returndfdeffilter_invalid(df):"""过滤明显无效的数据"""# 价格过滤:去掉明显异常价格df=df[(df['价格']>0)&(df['价格']<100000)]# 标题过滤:去掉标题太短(可能是广告位)df=df[df['标题'].str.len()>=5][video(video-5PyZV1DE-1781497152442)(type-csdn)(url-https://live.csdn.net/v/embed/524993)(image-https://v-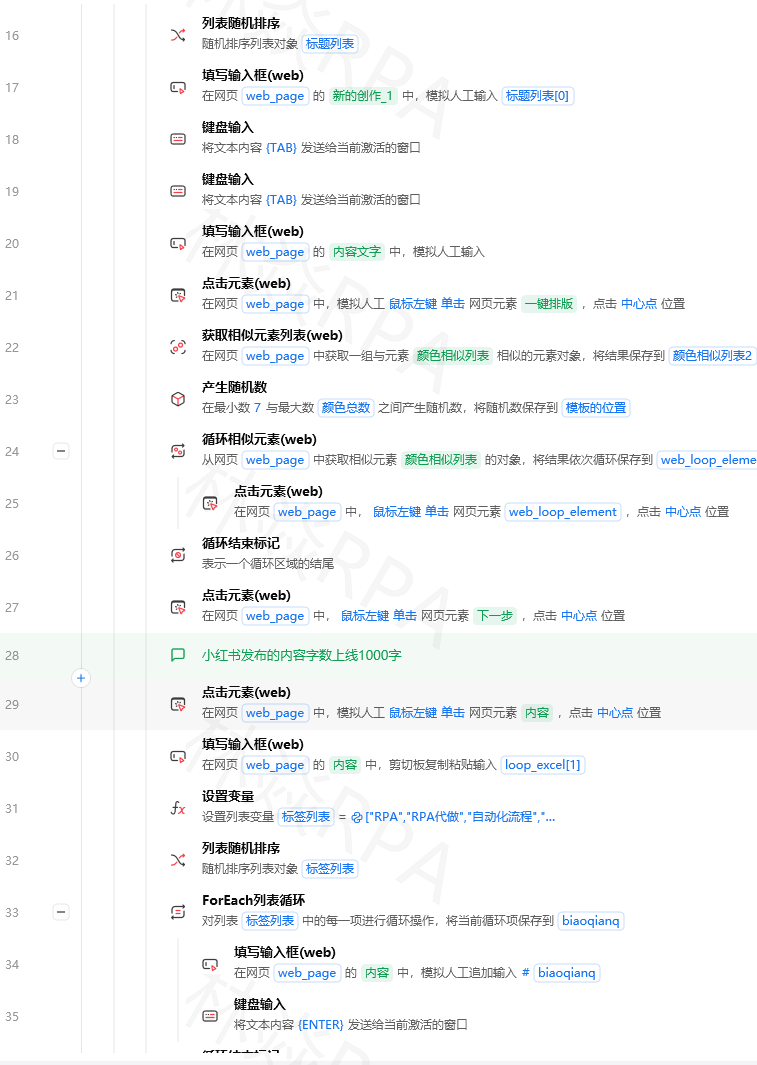blog.csdnimg.cn/asset/a547123d88ad712dccba346c9217e237/cover/Cover0.jpg)(title-TEMU店群如何管理运营?)]# 去掉关键字段为空的行df=df.dropna(subset=['标题','价格'])returndfdefclean_ecommerce_data(raw_file,output_file):"""一键清洗电商采集数据"""df=pd.read_excel(raw_file)# 依次应用清洗函数df['价格']=df['价格'].apply(clean_price)df['销量']=df['销量'].apply(cn_number_to_int)df['标题']=df['标题'].apply(clean_title)df['采集日期']=df['采集日期'].apply(normalize_date)df=enforce_types(df)df=filter_invalid(df)df=remove_duplicates(df)# 输出清洗结果df.to_excel(output_file,index=False)print(f'清洗完成:原始{len(pd.read_excel(raw_file))}行 → 清洗后{len(df)}行')在Python代码块中直接调用上面封装的函数:
# 完整流程:采集→清洗→写入raw_data=[/*影刀循环采集到的数据列表*/]df=pd.DataFrame(raw_data)# 清洗df['价格']=df['价格'].apply(clean_price)df['销量']=df['销量'].apply(cn_number_to_int)df=filter_invalid(df)# 写入df.to_excel(r'C:\数据\清洗结果.xlsx',index=False)最佳实践:把清洗函数单独保存到utils.py,影刀Python代码块里用import导入复用。
#影刀RPA #RPA自动化 #数据清洗 #Python数据处理 #电商数据
作者:林焱
本文为《影刀RPA学习手册》系列文章之一,内容源于实操经验的整理与分享。